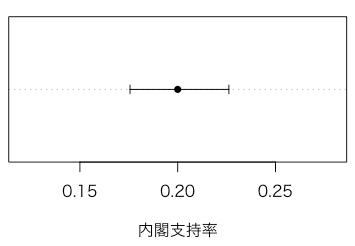
例えば1000人のうち200人が現内閣を支持すると答えたとすると,
> binom.test(200, 1000)
Exact binomial test
data: 200 and 1000
number of successes = 200, number of trials = 1000,
p-value < 2.2e-16
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.1756206 0.2261594
sample estimates:
probability of success
0.2
のように,内閣支持率 0.2(20%)の95%信頼区間が [0.176, 0.226] であることが求められます。
要は,「20%」と言っても,実際は 18% かも 22% かもしれず,1% や 2% の違いに意味はないというが結論です。
95%の信頼区間だけ求めたい場合は,binom.test(200, 1000)$conf.int と打ち込めばいいです。詳しくは binom.test のヘルプを参照して下さい。
慣れてきたら,図も書いてみましょう。
par(family="HiraKakuProN-W3") #mac cix = binom.test(200,1000)$conf.int dotchart(200/1000, pch=16, xlab="内閣支持率") arrows(cix[1], 1, cix[2], 1, length=0.05, angle=90, code=3)
信頼度を変えると幅がどう変わるのか,それも図示してみます。

par(family="HiraKakuProN-W3") #mac
par(mar=c(5,6,5,1))
par(cex=0.9)
cix1 = binom.test(200,1000, conf.level = 0.90)$conf.int
cix2 = binom.test(200,1000, conf.level = 0.95)$conf.int
cix3 = binom.test(200,1000, conf.level = 0.99)$conf.int
dotchart(c(0.2, 0.2, 0.2), pch=16, xlim=range(c(cix3,cix3)), xlab="内閣支持率")
arrows(cix1[1], 1, cix1[2], 1, length=0.05, angle=90, code=3)
arrows(cix2[1], 2, cix2[2], 2, length=0.05, angle=90, code=3)
arrows(cix3[1], 3, cix3[2], 3, length=0.05, angle=90, code=3)
mtext(c("信頼率90%","信頼率95%", "信頼率99%"), side=2, at=1:3, line=0.5, las=1)
では同じ支持率でも標本の大きさが変わるとどうなるでしょう。支持率は20%,信頼率は95%で固定し,標本数だけ変えてみます。すると次のようになります。標本数が多いほど信頼区間は狭くなることがわかります。
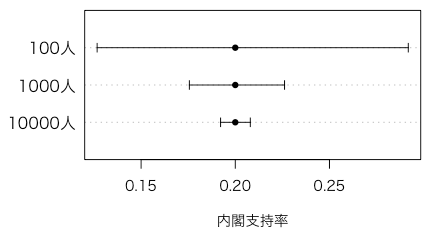
「信頼区間を狭くしたいのであれば,より大きい標本をとれ」の意味はこれでわかると思います。
par(family="HiraKakuProN-W3") #mac
par(mar=c(5,6,5,1))
par(cex=0.9)
cix1 = binom.test(2000,10000, conf.level = 0.95)$conf.int
cix2 = binom.test(200,1000, conf.level = 0.95)$conf.int
cix3 = binom.test(20,100, conf.level = 0.95)$conf.int
dotchart(c(0.2, 0.2, 0.2), pch=16, xlim=range(c(cix3,cix3)), xlab="内閣支持率")
arrows(cix1[1], 1, cix1[2], 1, length=0.05, angle=90, code=3)
arrows(cix2[1], 2, cix2[2], 2, length=0.05, angle=90, code=3)
arrows(cix3[1], 3, cix3[2], 3, length=0.05, angle=90, code=3)
mtext(c("10000人","1000人", "100人"), side=2, at=1:3, line=0.5, las=1)
ある地域で有権者2500人を任意抽出して,A政党の支持者を調べたところ1230人でした。この地域のA政党支持率を信頼度95%で推定して下さい。
では,R で計算してみます。
> binom.test(1230, 2500)
Exact binomial test
data: 1230 and 2500
number of successes = 1230, number of trials = 2500,
p-value = 0.4354
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.4722220 0.5117968
sample estimates:
probability of success
0.492
A政党の支持率 0.49(49%)の95%信頼区間は [0.472, 0.512] であることがわかります。
つまり,49%といっても,実際は 47% かも 51% かもしれないということです。
全国の有権者による現内閣の支持率を推定するために3000人の有権者を無作為抽出して調べたところ,支持者は1050人でした。全有権者での支持率を95%の信頼度で区間推定して下さい。(広田すみれ『読む統計学 使う統計学』p.160)
> binom.test(1050, 3000)
Exact binomial test
data: 1050 and 3000
number of successes = 1050, number of trials = 3000,
p-value < 2.2e-16
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.3329187 0.3673743
sample estimates:
probability of success
0.35
内閣支持率は 0.35(35%)の95%信頼区間は [0.333, 0.367] であることがわかります。
日本経済新聞社が2003年9月に実施した大きさ11000サンプルの世論調査によれば,小泉内閣の支持率は65%でした。有権者全体での支持率を90%の信頼度で区間推定して下さい。
> binom.test(11000*0.65, 11000, conf.level = 0.9)
Exact binomial test
data: 11000 * 0.65 and 11000
number of successes = 7150, number of trials = 11000,
p-value < 2.2e-16
alternative hypothesis: true probability of success is not equal to 0.5
90 percent confidence interval:
0.6424454 0.6574958
sample estimates:
probability of success
0.65
内閣支持率65%の90%信頼区間は [0.642, 0.657] であることがわかります。
内閣支持率の調査において,信頼係数 95% の信頼区間の幅を点推定値の上下 2.5% 以内に抑えたかったら,標本サイズ n はどれくらいに設定するべきか。
n ≧ 1600
次の意見を批評しなさい。
内閣支持率の調査などというものは,あてにならない。有権者は数千万人いるのに,そのごく一部でしかない数百人程度の人を調べて結果を出しているからだ。もしも有権者が1500人しかないのなら,そのうち500人も調べれば全体の1/3を調べたことになり,ある程度は全体の傾向を反映した結果が出ると期待できるが,有権者が9000万人いるとしたら,同じ程度の確からしさで結果を出すには,3000万人ぐらいを調べなければならないだろう。数百人などというのは話にならない。
(出典)三土修平『ミニマムエッセンス 統計学』p144
(解答例)
この主張の主は,内閣支持率の推定の精度は母集団のサイズ N に対する標本サイズ n の比に依存し,分数 n/N を大きくしなければ精度は上がらないと考えている。しかし,これは誤りで,標本抽出の無作為性が確保されているかぎり,n を増大させれば信頼区間の幅は着実に狭まっていくのであり,N はその精度の決定には基本的に関与していない。精度を増すために数百とか数千とかの数に設定した n が,N に対して取るに足らないほど小さな数であったとしても,それは構わないのである。
ある町の駅で乗降客400人を任意抽出して調べたところ,196人がその町の住人でした。乗降客の中でその町の住人の比率を信頼度99%で推定して下さい。
この問題では信頼度が99%であることに注意です。R で計算する際,conf.level=0.99 というオプションを忘れないように。
> binom.test(196, 400, conf.level = 0.99)
Exact binomial test
data: 196 and 400
number of successes = 196, number of trials = 400,
p-value = 0.7264
alternative hypothesis: true probability of success is not equal to 0.5
99 percent confidence interval:
0.4248093 0.5554335
sample estimates:
probability of success
0.49
住人の比率 0.49(49%)の99%信頼区間は [0.425, 0.555] であることがわかります。
ある原野に,A,B 2種の野ネズミが生息しています。任意に300匹の野ネズミを捕まえたところ,A種が90匹いました。A種の野ネズミは,この原野全体で何%生息していると考えられますか。信頼度95%で推定して下さい。
> binom.test(90, 300)
Exact binomial test
data: 90 and 300
number of successes = 90, number of trials = 300,
p-value = 3.305e-12
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.2486816 0.3553195
sample estimates:
probability of success
0.3
標本比率 0.3(30%)の95%信頼区間は [0.248, 0.355] であることがわかります。
par(family="HiraKakuProN-W3") #mac
par(las=1)
v = 2; n = 10 #母分散と標本の大きさ
d = qnorm(0.975)*sqrt(v/n) #95%信頼区間の幅
x = c(-2.5, -2.5, 2.5, 2.5)
y = c(0, 100, 100, 0)
plot(x, y, type = "n", xlab = "", ylab = "")
segments(0,0,0,100,col="red")
for (i in 0:100){
r = rnorm(n, mean=0, sd=sqrt(v))
m = mean(r)
segments(m-d, i, m+d, i)
points(m, i, pch=4, col="red", cex=0.8)
if (m-d>0 || m+d<0) text(-2.5,i,"*")
}
title(main="N(0, 2) から大きさ10の標本から得られた\n平均μの95%信頼区間を100回作成",
cex.main=1.0)