有意水準は5%で検定を3回繰り返すと,それぞれの有意水準は5%でも,合計すると有意水準は15%まで増える可能性がある。
有意水準が増えるということは“仮説を捨てやすくなる”ということなので,もともと有意差が無かったにもかかわらず,差があったかのように仮説を棄却してしまう危険性がある。
PISAの盗難事件
あるTVレポーターがグラフを示して,「1999年は1998年に比べて,盗難事件が激増しています」と言いました。1999年は516件,1998年は508件です。このレポーターの説明は適切でしょうか。考えてみましょう。
盗難事件が1998年に起きる確率も1999年に起きる確率も等しいという帰無仮説を立てて,検定してみましょう。
レポーターの意見は盗難事件が増えた,なので
$H_{1}$ は $\mu > 0.5$(対立仮説)
帰無仮説は“確率は変わらない”すなわち,以下のように仮定する。
$H_{0}$ は $\mu = 0.5$(帰無仮説)
まずは R で。
> binom.test(508, 508+516, 0.5)
Exact binomial test
data: 508 and 508 + 516
number of successes = 508, number of trials = 1024,
p-value = 0.8269
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.4650308 0.5271792
sample estimates:
probability of success
0.4960938
p = 0.8269 なので違いがあるとはいえません。
p値だけ求めたい場合は,binom.test(508, 508+516, 0.5)$p.value と打ち込めばいいです。詳しくは binom.test のヘルプを参照して下さい。
ある大学では,毎年新入生全員約3000人に,同一の問題を用いた英語の試験を実施しています。過去の試験の成績 $x$ は平均450点,標準偏差80点の正規分布で近似されます。
さて,今年の新入生のうち,ある教員が担当するクラスで $n = 36$ 人の成績を調べたところ,次のような点数でした。
479, 520, 521, 541, 596, 488, 486, 520, 309, 475, 428, 543, 417, 417, 550, 524, 626, 452, 384, 555, 403, 481, 364, 569, 379, 546, 632, 504, 332, 522, 545, 436, 537, 451, 335, 407
このクラスの結果から新入生全体で英語力に変化があったと判断できるか考えてみましょう。
(統計検定2級,p154)
計画フェーズで,データ収集の計画を立てます。
母集団を今年の新入生全員として,標本をあるクラスに属する学生36名とします。
標本に選んだ“あるクラスに属する学生”は無作為標本ではありませんが,今年の新入生全員の代表と,ここでは仮定します。
彼らの英語の成績の点数データを集め,それを$x_{1}, ..., x_{n}$ とします。
$H_{1}$ は $\mu \neq 450$(対立仮説)
帰無仮説は “今年の新入生の英語の成績の平均は変わらない” すなわち,以下のように仮定します。
$H_{0}$ は $\mu = 450$(帰無仮説)
有意水準を5%と置き,両側検定を行います。データをもとに,対立仮説が正しいかどうかを判断します。
まずは以下のようにデータをまとめておきます。
score=c(479,520,521,541,
596,488,486,520,
309,475,428,543,
417,417,550,524,
626,452,384,555,
403,481,364,569,
379,546,632,504,
332,522,545,436,
537,451,335,407)
母分散が未知の場合も考えてみましょう。この場合はt検定を適用します。
R の t.test コマンドを使って計算してみます。
> t.test(score, mu=450) One Sample t-test data: score t = 2.1816, df = 35, p-value = 0.03594 alternative hypothesis: true mean is not equal to 450 95 percent confidence interval: 452.0715 507.5952 sample estimates: mean of x 479.8333
$t_{obs} = 2.1816$ となります。
$p = P(|T|\geq2.1816) = 0.036 < 0.05$ で,有意であり,帰無仮説を棄却します。したがって,今年の新入生の英語の成績の平均は450点とは異なると言えます。
結論フェーズでは,分析結果をもとに結論を導き,具体的な改善策につなげます。
分析結果が,今年の新入生の英語の成績の平均は450点と異なることを示していることにより,新入生の英語力に変化があったと結論づけます。
考察として,Listening, Reading など,分野別に英語力に変化があったかについて調べることで,授業の改善方法へつなげるなど,次の課題へ発展できます。
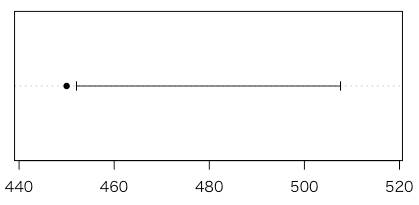
信頼区間を用いて,両側対立仮説が正しいかどうか判断する方法についても説明しておきます。
分散が未知の場合,母平均$\mu$の信頼係数0.95の信頼区間は [452.072, 507.595] と求められます。帰無仮説のもとでの $\mu$ の値である $\mu_{0} = 450$ が信頼区間に含まれていません。これにより,母平均$\mu$ が $\mu_{0}$ と異なると判断することができます。
上の信頼区間のグラフのソースは次の通りです。
par(family="HiraKakuProN-W3") #mac par(mar=c(5,2,5,2)) par(cex=0.9) cix = t.test(score,conf.level = 0.95)$conf.int dotchart(c(450), pch=16, xlim=range(c(cix-10,cix+10))) arrows(cix[1], 1, cix[2], 1, length=0.05, angle=90, code=3)
工事中
工事中
工事中